
You are currently browsing the tag archive for the ‘dispersion’ tag.
Negative binomial observations naturally appears in many biological applications, such as in genomics. This article describes the details of the likelihood-ratio test to determine if two sets of observations come from the same negative binomial distribution or not. Given probability of failure 

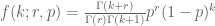
where 
For likelihood-ratio test one needs to find the maximum likelihood solution of 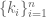

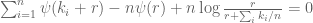
where 
However, this approach problematic when the observations are only slightly over-dispersed, i.e., they resemble Poisson distribution. In this case, 
To tackle this issue, a reparameterization of negative binomial distribution is suggested in terms of dispersion parameter 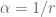
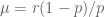
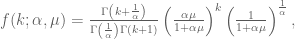
and the maximum likelihood estimator of 

![\mathrm{G} = \frac{1}{\alpha^2}\left[-\sum_i \psi\left(k_i + \frac{1}{\alpha}\right) + n\psi\left(\frac{1}{\alpha}\right) + n\log(1 + \alpha\mu)\right],](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BG%7D+%3D+%5Cfrac%7B1%7D%7B%5Calpha%5E2%7D%5Cleft%5B-%5Csum_i+%5Cpsi%5Cleft%28k_i+%2B+%5Cfrac%7B1%7D%7B%5Calpha%7D%5Cright%29+%2B+n%5Cpsi%5Cleft%28%5Cfrac%7B1%7D%7B%5Calpha%7D%5Cright%29+%2B+n%5Clog%281+%2B+%5Calpha%5Cmu%29%5Cright%5D%2C&bg=ffffff&fg=545454&s=0&c=20201002)
![\mathrm{H} = \frac{1}{\alpha^4}\left[\sum\psi'\left( k_i +\frac{1}{\alpha} \right) + 2\alpha \sum_i \psi\left( k_i + \frac{1}{\alpha} \right) - n \psi'\left(\frac{1}{\alpha}\right) - 2n \alpha \psi\left(\frac{1}{\alpha}\right) + n\alpha \left( \frac{\mu\alpha}{1 + \mu\alpha} - 2\log(1 + \mu\alpha)\right)\right],](https://s0.wp.com/latex.php?latex=%5Cmathrm%7BH%7D+%3D+%5Cfrac%7B1%7D%7B%5Calpha%5E4%7D%5Cleft%5B%5Csum%5Cpsi%27%5Cleft%28+k_i+%2B%5Cfrac%7B1%7D%7B%5Calpha%7D+%5Cright%29+%2B+2%5Calpha+%5Csum_i+%5Cpsi%5Cleft%28+k_i+%2B+%5Cfrac%7B1%7D%7B%5Calpha%7D+%5Cright%29+-+n+%5Cpsi%27%5Cleft%28%5Cfrac%7B1%7D%7B%5Calpha%7D%5Cright%29+-+2n+%5Calpha+%5Cpsi%5Cleft%28%5Cfrac%7B1%7D%7B%5Calpha%7D%5Cright%29+%2B+n%5Calpha+%5Cleft%28+%5Cfrac%7B%5Cmu%5Calpha%7D%7B1+%2B+%5Cmu%5Calpha%7D+-+2%5Clog%281+%2B+%5Cmu%5Calpha%29%5Cright%29%5Cright%5D%2C&bg=ffffff&fg=545454&s=0&c=20201002)
and Newton’s update rule can then be written as

The iteration can be initiated with the moments estimate

Notice that when the observations are underdispersed then this quantity is negative. In such cases, and in situations when the observations are only slightly overdispersed, i.e., this quantity is very close to zero, the estimate of gradient and Hessian might be unstable. Therfore, it is safer to assign
A Matlab implementation of this test can be found here.
[1] “Estimating the Negative Binomial Dispersion Parameter“, Mohanad F. Al-Khasawneh, Asian Journal of Mathematics and Statistics 3 (1), 1-15, 2010, ISSN 1994-5418
